
You’ve probably heard traders talk about the order book before: it’s one of the most fundamental tools in modern markets. It’s a very important tool for traders, analysts or quants. A trading order book is a real-time record of all buy and sell orders for a financial asset, like a stock, bond, or cryptocurrency, organized by price level. How does it work and why does it matter?
What’s a Trading Order Book?
An order book is a real-time, organized list of buy and sell orders for a financial asset, arranged by price level and volume. It reflects market depth: the amount of demand and supply available at each price.

In essence:
- Buy orders (bids): traders wanting to purchase, listed from highest to lowest price.
- Sell orders (asks): traders wanting to sell, listed from lowest to highest price.

Each entry includes a price and a quantity. When a buy and sell order meet at the same price, a trade executes, removing both from the book.
The best bid is the highest price someone will pay.
The best ask is the lowest price someone will sell for.
The spread is the difference between the two — a key measure of liquidity.
Order books help traders understand supply, demand, and short-term price movements, forming the foundation for price discovery in modern markets.
How Does it Work?
This image illustrates how an order book works by showing the interaction between buyers (bids) and sellers (asks) for a currency pair.
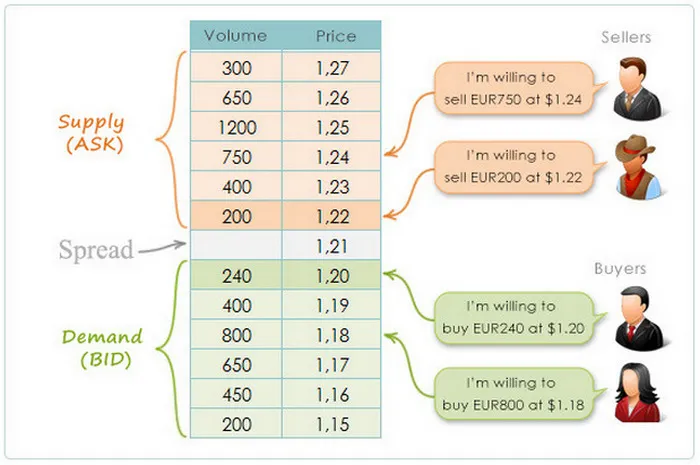
On the right, you see two groups of participants:
- Sellers (Supply / ASK) list the prices at which they’re willing to sell.
- Buyers (Demand / BID) list the prices at which they’re willing to buy.
The table in the middle displays these orders:
- The top half (orange) represents sell orders. Each row shows a price and the volume available at that price. For example, one seller wants to sell EUR 200 at $1.22, another EUR 750 at $1.24.
- The bottom half (green) represents buy orders. For instance, a buyer wants to buy EUR 240 at $1.20, another EUR 800 at $1.18.
Between them lies the spread, the small gap between the highest bid (best buyer) and the lowest ask (best seller). In this example, the spread is $0.01 (between $1.20 and $1.21).
This spread reflects the liquidity and balance of supply and demand — tighter spreads usually mean a more liquid market. When a market order arrives, it executes at the best available price from these existing limit orders, causing the market price to update.
The Importance of the Bid-Ask Spread
The spread is the gap between the best ask (lowest price a seller accepts) and the best bid (highest price a buyer offers).
It represents the cost of immediacy: how much extra a trader pays to buy right now or how much less they get to sell immediately.
A tight spread means a liquid, competitive market with many buyers and sellers.
A wide spread suggests uncertainty, low liquidity, or higher risk.
For pricers, the spread is both a signal and a target.
They aim to quote prices that are competitive enough to attract trades but wide enough to cover risks.
Too narrow, and they might lose money to fast market moves.
Too wide, and they risk losing flow to other participants.
So, pricers constantly adjust their spreads based on volatility, order flow, inventory, and competition balancing profitability with market presence.
How To Implement a Trading Order Book in C++?
Here’s a compact blueprint for a limit-order book in C++: data layout, core ops, and gotchas. We will:
- Maintain two sides: bids (max-first) and asks (min-first).
- Group orders by price level; within a level, keep FIFO (price–time priority).
- Keep a fast index from order_id → node/iterator to support O(1) cancel/replace.
- Use integer ticks (e.g., cents, pips) — avoid floating point for prices.
using OrderId = uint64_t;
using Qty = int64_t; // signed for partial fills math
using Px = int64_t; // price in ticks
enum Side { Buy, Sell };
struct Order {
OrderId id;
Side side;
Px price;
Qty qty; // remaining
uint64_t ts; // exchange/seq time for tie-breaks
// intrusive list pointers for O(1) erase
Order* prev = nullptr;
Order* next = nullptr;
};
struct Level {
Px price;
Order* head = nullptr;
Order* tail = nullptr;
inline void push_back(Order* o);
inline void erase(Order* o);
bool empty() const { return head == nullptr; }
};
// price → level; bids need descending, asks ascending
using BookSide = std::map<Px, Level, std::greater<Px>>; // bids
using BookSideAsk = std::map<Px, Level, std::less<Px>>; // asks
struct OrderBook {
BookSide bids;
BookSideAsk asks;
std::unordered_map<OrderId, Order*> by_id; // direct handle for cancel/replace
// API
void add_limit(OrderId id, Side side, Px px, Qty qty, uint64_t ts);
void cancel(OrderId id);
void replace(OrderId id, Px new_px, Qty new_qty, uint64_t ts); // cancel+add semantics
void match_market(Side side, Qty qty);
// helpers
Level& level(BookSide& s, Px px);
Level& level(BookSideAsk& s, Px px);
};
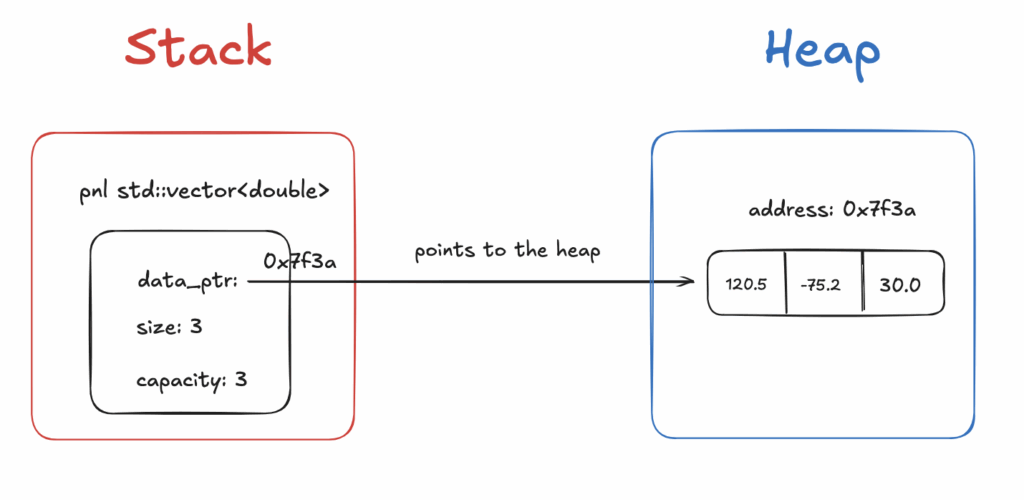
The C++ order book example keeps two ordered maps: one for bids (descending prices) and one for asks (ascending). Each price level stores a queue of orders to preserve price–time priority. Each order holds its ID, side, price (as an integer tick), quantity, and pointers to neighboring orders for quick removal. A
n additional hash map links every order ID to its memory address, allowing O(1) cancellation or modification. When a new limit order arrives, it matches existing orders on the opposite side if the prices overlap; otherwise, it’s added to the appropriate queue. Market orders consume orders starting from the best available price. The design avoids floating-point precision issues by using integers, and it minimizes heap allocations through object pooling. Operations within a price level run in constant time, while finding the best price is logarithmic. The result is a fast, deterministic system that mirrors how real exchanges match and update orders.
The Challenges for Pricers: Find the Mid
For pricers, one of the core challenges is finding the true mid-price: the fair point between supply and demand. In theory, the mid is simply the average of the best bid and best ask, but in practice it’s far more complex. The visible quotes in the order book might not reflect real interest, as large traders often hide size or layer orders strategically.
The mid can also move rapidly in volatile markets, making it difficult for pricers to keep up without overreacting to noise. Liquidity imbalances, or instance, when one side of the book is much deeper than the other, distort the apparent equilibrium. Moreover, different trading venues might show slightly different best prices, forcing pricers to aggregate data across markets.
Latency adds another layer of uncertainty: by the time data is received, the true mid might have shifted. Pricers must therefore estimate a “synthetic mid”, balancing recent trades, book depth, and volatility signals. Their goal is to quote competitively around this mid without exposing themselves to adverse selection. The challenge lies in constantly adapting: finding the mid not as a static number, but as a moving, data-driven target that defines the heartbeat of market making.
How to Develop a Pricer: Train an ML Model to Predict the Mid
Developing a pricer that uses machine learning to estimate the mid-price involves combining market microstructure knowledge with careful model design. The goal is to predict the true or future mid (the fair value where supply and demand balance) based on high-frequency order book data.
The process starts with data collection: capturing snapshots of the limit order book, trades, and quote updates with precise timestamps. Each snapshot provides features such as best bid/ask, spread, market depth, imbalance (volume difference between bid and ask sides), last trade direction, and short-term volatility. These become the inputs to the model.
Next comes labeling. A common choice is the future mid, for example the mid-price 1–5 seconds ahead. This trains the model to learn short-term price dynamics rather than just the current quote.
The model selection depends on latency and interpretability requirements. For low-latency environments, ML models like gradient-boosted trees (like XGBoost or LightGBM) work well. For richer patterns, temporal architectures such as CNNs, LSTMs, or Transformers on order book sequences capture evolving microstructure dynamics.
Once trained, the model’s predicted mid becomes the reference for quoting: bids are set slightly below and asks slightly above it, adjusted for volatility, inventory, and risk tolerance.
The main challenges lie in data quality, microsecond synchronization, feature drift, and ensuring the model generalizes under changing market regimes. Continuous retraining and real-time monitoring are essential. In essence, the ML pricer learns to “feel” the market’s equilibrium — a constantly shifting target driven by flow, depth, and momentum.
Conclusion
In conclusion, an order book is the foundation of market mechanics, recording all buy and sell intentions that together form price discovery. The spread, the gap between the best bid and ask, reflects market liquidity and trading costs — a narrow spread means efficiency, while a wide one signals risk or low activity. For pricers, managing and interpreting that spread is crucial: they must stay competitive while protecting against adverse moves. Finding the true mid between supply and demand is not trivial; it fluctuates constantly with market depth, hidden orders, and volatility. Modern pricers therefore rely on machine learning models to estimate the fair or future mid, using features like order-book imbalance, volume, and trade flow. These models learn to sense microstructure dynamics and help automate quoting decisions in real time. Building such systems is both a technical and strategic challenge, requiring clean data, synchronized feeds, fast inference, and constant retraining to stay aligned with a living, breathing market.