
One of the most important topics in C++ is parallel programming. While the C++ Standard Library provides foundational concurrency primitives such as std::thread, std::mutex, and std::async, or more recent SIMD additions, many real-world applications benefit from higher-level abstractions. Modern parallel programming libraries offer task schedulers, work-stealing runtimes, dependency graphs, distributed execution models, and performance-portable frameworks that dramatically simplify the development of scalable systems. What are the best C++ libraries for parallel programming?
1. OpenMP
OpenMP (Open Multi-Processing) is an open standard for shared-memory parallel programming that allows developers to parallelize code using compiler directives, library routines, and environment variables. It’s one of the best C++ libraries for parallel programming.
It was first introduced in 1997 by the OpenMP Architecture Review Board (ARB), a consortium of hardware and software companies that included organizations such as Intel, IBM, Hewlett-Packard, and others. The goal was to create a portable and vendor-neutral standard for exploiting multiple CPU cores on shared-memory systems.
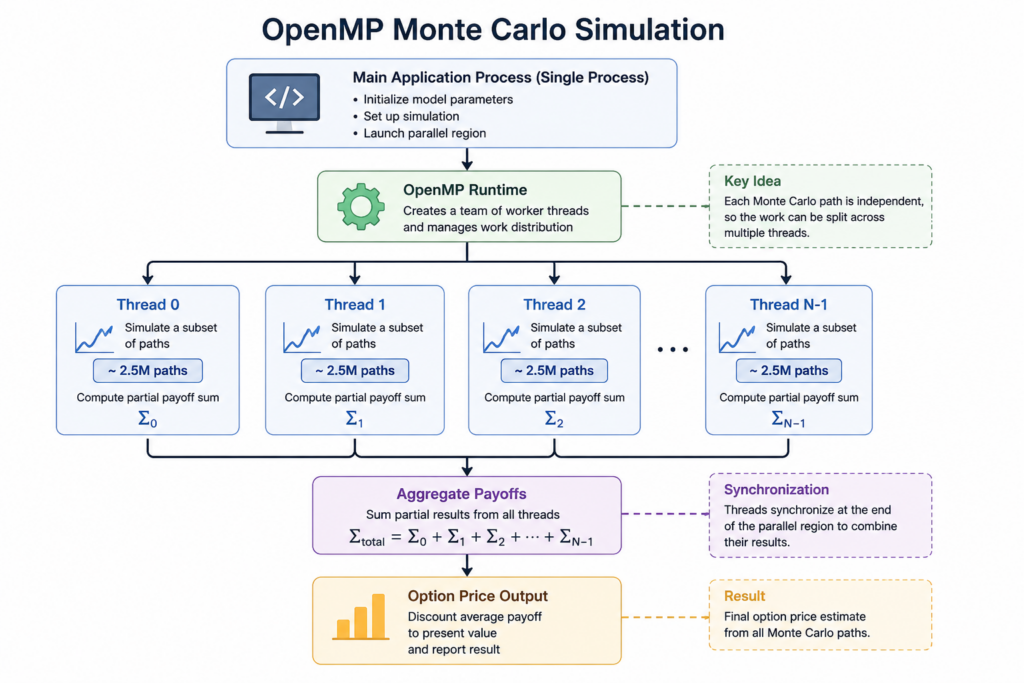
Monte Carlo pricing is a classic example of an embarrassingly parallel workload. By distributing simulation paths across multiple CPU cores, OpenMP can significantly reduce execution times with only a few additional lines of code.
Let’s create a “monte_carlo.cpp” file:
#include <omp.h>
#include <cmath>
#include <random>
#include <vector>
#include <iostream>
double simulate_option_price(
double spot,
double strike,
double rate,
double vol,
double maturity,
int num_paths)
{
double payoff_sum = 0.0;
#pragma omp parallel
{
std::mt19937 rng(42 + omp_get_thread_num());
std::normal_distribution<> normal(0.0, 1.0);
double local_sum = 0.0;
#pragma omp for
for (int i = 0; i < num_paths; ++i)
{
double z = normal(rng);
double st =
spot * std::exp(
(rate - 0.5 * vol * vol) * maturity +
vol * std::sqrt(maturity) * z);
local_sum += std::max(st - strike, 0.0);
}
#pragma omp atomic
payoff_sum += local_sum;
}
return std::exp(-rate * maturity) * payoff_sum / num_paths;
}
int main()
{
double price = simulate_option_price(
100.0,
100.0,
0.05,
0.20,
1.0,
10'000'000);
std::cout << "Option Price: " << price << '\n';
}In the code above, each thread is responsible for a portion of the Monte Carlo simulations. Because individual simulation paths are completely independent, they can be executed concurrently on multiple CPU cores before their results are aggregated into a final option price estimate.
Compiling the Example
OpenMP is implemented through compiler support rather than as a standalone library. When the compiler encounters OpenMP directives such as #pragma omp parallel or #pragma omp for, it generates the necessary multithreaded code and links against the OpenMP runtime.
To compile the example using GCC:
g++ -O3 -fopenmp monte_carlo.cpp -o monte_carloThe -fopenmp flag enables OpenMP support and links the OpenMP runtime library. Without this flag, the compiler will ignore the OpenMP directives and execute the code sequentially.
On macOS, the default Apple Clang compiler does not always include OpenMP support. In this case, developers typically install LLVM or GCC through Homebrew and compile the program using an OpenMP-enabled compiler.
Then execute the code:
./monte_carloThe simulation above will be split on different threads before an aggregation step:
2.oneTBB
oneTBB (formerly Intel Threading Building Blocks) is a task-based parallel programming library created by Intel and first released in 2006. Rather than managing threads directly, developers express work as tasks, allowing oneTBB’s scheduler to efficiently distribute computation across multiple CPU cores.
Widely used in high-performance computing, quantitative finance, and scientific applications, oneTBB provides parallel algorithms, concurrent containers, and a work-stealing scheduler designed to simplify scalable multicore development.
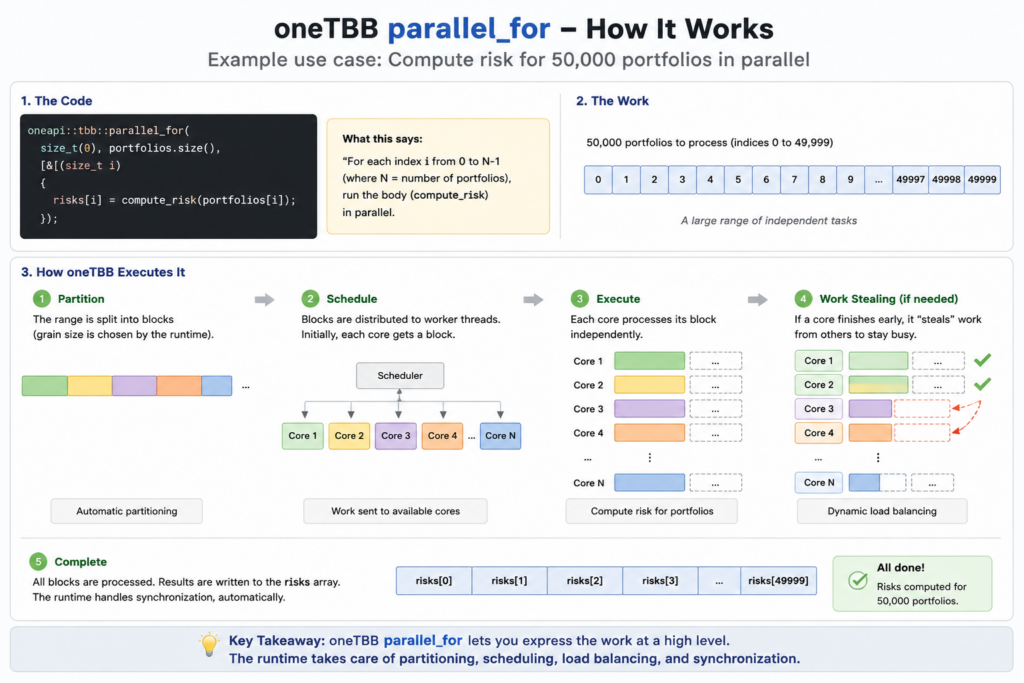
A bank needs to recompute a risk metric for 50,000 portfolios after a market move. Since each portfolio can be processed independently, the workload is naturally parallel. Instead of manually creating and managing threads, oneTBB distributes the portfolios across available CPU cores and balances the work automatically.
#include <oneapi/tbb/parallel_for.h>
#include <vector>
struct Portfolio
{
std::string portfolio_id;
std::vector<double> trade_dv01s;
};
double compute_risk(const Portfolio& portfolio)
{
double dv01 = 0.0;
for(double trade_dv01 : portfolio.trade_dv01s)
{
dv01 += trade_dv01;
}
return dv01;
}
int main()
{
std::vector<Portfolio> portfolios(50000);
std::vector<double> risks(portfolios.size());
oneapi::tbb::parallel_for(
size_t(0),
portfolios.size(),
[&](size_t i)
{
risks[i] = compute_risk(portfolios[i]);
});
return 0;
}In this example, each portfolio can be evaluated independently, making the workload embarrassingly parallel. The parallel_for algorithm automatically divides the portfolio universe into smaller chunks and schedules them across available CPU cores. Unlike traditional thread-based approaches, developers do not need to manage thread creation, synchronization, or load balancing manually. This allows applications to scale efficiently on multicore systems while keeping the code concise and maintainable.
3.TaskFlow
Taskflow is a modern C++ parallel programming library that allows developers to express applications as task dependency graphs (DAGs) rather than individual threads or loops. It automatically schedules tasks, manages dependencies, and executes workflows efficiently across available CPU cores, making it particularly well-suited for data pipelines, simulations, and complex computational workflows. Taskflow is one the best C++ libraries for parallel programming.

The project was first presented publicly in 2019 as “Cpp-Taskflow: Fast Task-Based Parallel Programming Using Modern C++”.
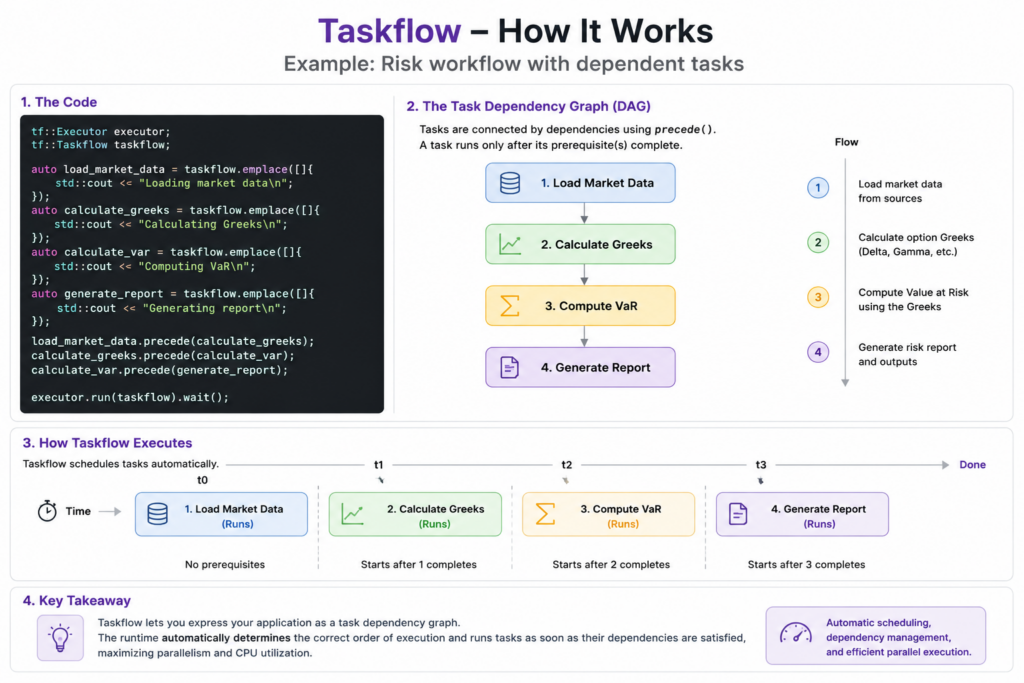
The following example models a simple risk analytics pipeline. Market data must be loaded before risk calculations can begin, while independent calculations can run in parallel. Once all computations are complete, a report is generated
#include <taskflow/taskflow.hpp>
int main() {
tf::Executor executor;
tf::Taskflow taskflow;
auto load_market_data = taskflow.emplace([]{
std::cout << "Loading market data\n";
});
auto calculate_greeks = taskflow.emplace([]{
std::cout << "Calculating Greeks\n";
});
auto calculate_var = taskflow.emplace([]{
std::cout << "Computing VaR\n";
});
auto generate_report = taskflow.emplace([]{
std::cout << "Generating report\n";
});
load_market_data.precede(calculate_greeks);
calculate_greeks.precede(calculate_var);
calculate_var.precede(generate_report);
executor.run(taskflow).wait();
}Unlike OpenMP and oneTBB, which primarily focus on parallel loops and tasks, Taskflow allows developers to express entire applications as dependency graphs. Independent tasks can execute concurrently, while dependent tasks automatically wait for their prerequisites to complete. This approach is particularly useful for data pipelines, machine learning workflows, risk calculations, and other complex computational processes.
4.HPX
HPX is a modern C++ runtime system designed for scalable parallel and distributed applications. It extends the C++ standard library with asynchronous programming primitives such as futures, parallel algorithms, and task scheduling, allowing developers to write code that can scale from a laptop to a large computing cluster with minimal changes.

Typical Use Cases
- Scientific computing
- Distributed simulations
- Numerical methods
- Large-scale graph processing
- HPC applications
- Quantitative finance workloads requiring cluster-scale execution
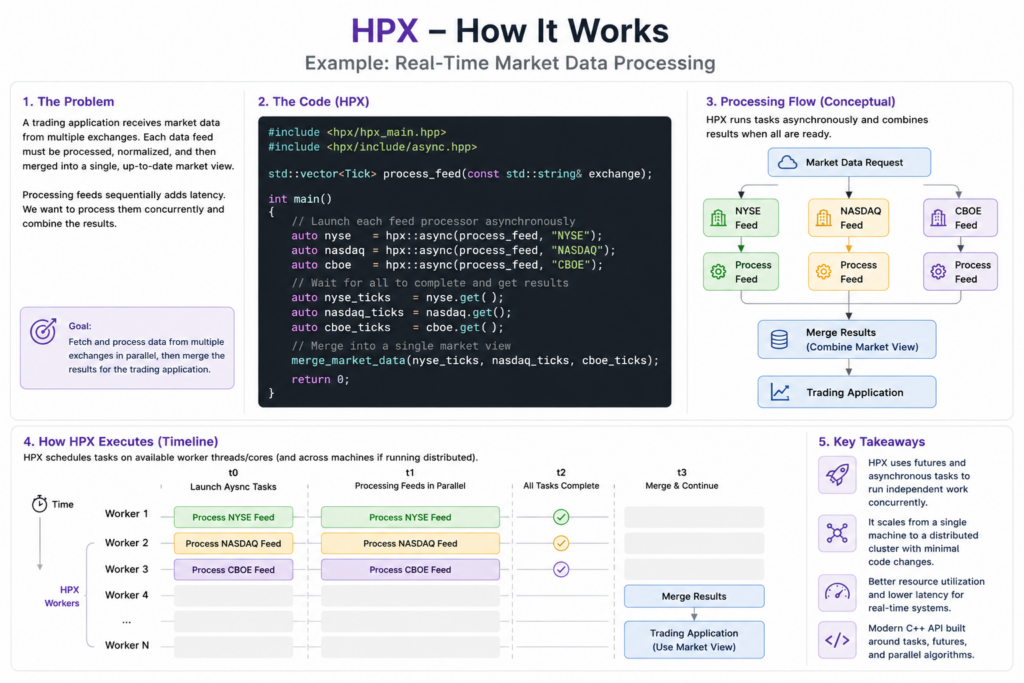
Imagine a trading platform receives market data from multiple exchanges. Instead of processing each feed sequentially, HPX can launch asynchronous tasks and combine the results once all feeds have been processed.
#include <hpx/hpx_main.hpp>
#include <hpx/include/async.hpp>
std::vector<Tick> process_feed(const std::string& exchange);
int main()
{
auto nyse = hpx::async(process_feed, "NYSE");
auto nasdaq = hpx::async(process_feed, "NASDAQ");
auto cboe = hpx::async(process_feed, "CBOE");
auto nyse_ticks = nyse.get();
auto nasdaq_ticks = nasdaq.get();
auto cboe_ticks = cboe.get();
merge_market_data(
nyse_ticks,
nasdaq_ticks,
cboe_ticks
);
}In this example, market data from multiple exchanges is processed concurrently using HPX futures. Each feed is handled asynchronously, allowing the application to utilize available computing resources efficiently while avoiding unnecessary blocking. Once all tasks complete, the results are merged into a unified market view.
In summary, HPX is one of the best C++ libraries for parallel programming!
5. A Summary of Pros and Cons
The libraries covered in this article address different parallel programming challenges, from simple loop parallelism to task scheduling, workflow orchestration, and distributed execution. The best choice depends on the complexity of your workload and how much control you need over execution.
| Library | Strengths | Weaknesses |
|---|---|---|
| OpenMP | Easy to learn, simple loop parallelism, broad compiler support | Limited flexibility for complex task dependencies |
| oneTBB | Task-based programming, automatic load balancing, scalable runtime | More concepts to learn than OpenMP |
| Taskflow | Elegant workflow graphs (DAGs), intuitive dependency management | Smaller ecosystem and fewer learning resources |
| HPX | Futures, asynchronous execution, distributed computing support | Steeper learning curve and more advanced programming model |
Choosing the Right Library
- OpenMP is ideal when you need to parallelize loops with minimal code changes.
- oneTBB is a strong choice for applications composed of many independent tasks.
- Taskflow excels at modelling complex workflows with explicit dependencies.
- HPX is designed for highly scalable asynchronous applications that may span multiple machines.
In short: OpenMP focuses on loops, oneTBB on tasks, Taskflow on workflows, and HPX on asynchronous and distributed execution. Together, they represent a progression from straightforward multicore programming to advanced parallel and distributed systems.